
GeneSpeak¶
A library to encode text as DNA and decode DNA to text.
GeneSpeak allows you to encode regular text as DNA using base-pairs (A, T, G, C) and convert back to the original text. Text encoding is done for both ascii and utf-8 characters based on the strategy keyword argument.
Background¶
A DNA molucule consists of a double-helix, where each strand is composed of a series of bases from the following four types:
- Adenine (A)
- Cytosine (C)
- Guanine (G)
- Thymine (T)
Adenine pairs with thymine, and cytosine pairs with guanine.
- A – T
- C – G
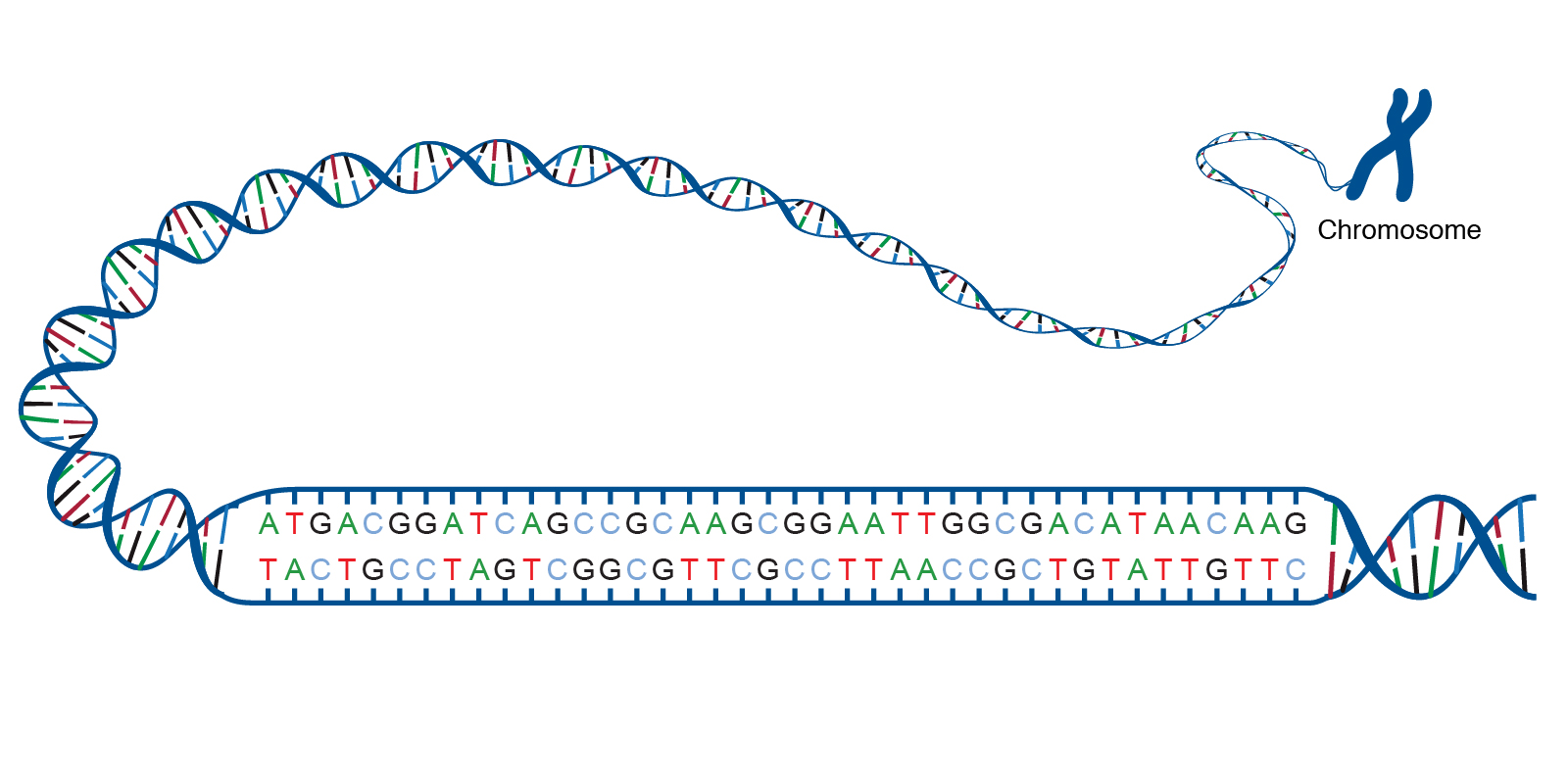 |
|---|
| Source: https://www.genome.gov/genetics-glossary/acgt |
Installation¶
You can install the library via pip or conda.
Install with pip
pip install genespeak
Install with conda
conda install -c conda-forge genespeak
Usage¶
import genespeak as gp
print(f'{gp.__name__} version: {gp.__version__}')
schema = "ATCG" # (1)
strategy = "ascii" # (2)
text = "Hello World!"
dna = gp.text_to_dna(text, schema=schema, strategy=strategy)
text_from_dna = gp.dna_to_text(dna, schema=schema, strategy=strategy)
print(f'Text: {text}\nEncoded DNA: {dna}\nDecoded Text: {text_from_dna}\n')
-
The
schemaparameter is used to determine how the text-to-dna conversion will be encoded. There are 24 possible values for schema:ACTG,AGCT,TACG,CATG, etc. -
The
strategyparameter determines whether to treat the text as ascii-only (strategy="ascii") or as utf-8 (strategy="utf-8"). For non-english text, or text with emojis, theutf-8strategy must be used.
Output
genespeak version: 0.0.5
Text: Hello World!
Encoded DNA: TACATCTTTCGATCGATCGGACAATTTGTCGGTGACTCGATCTAACAT
Decoded Text: Hello World!